
Правильный robots.txt
Всем нужны инструкции для работы, поисковые системы не исключения из правил, поэтому и придумали специальный файл под названием robots.txt. Этот файл должен лежать в корневой папке вашего сайта, или он может быть виртуальным, но обязательно открываться по запросу: www.вашсайт.ru/robots.txt
Поисковые системы уже давно научились отличать нужные файлы html, от внутренних наборов скриптов вашей CMS системы, точнее они научились распознавать ссылки на контентные статьи и всяких хлам. Поэтому многие вебмастера уже забывают делать роботс для своих сайтов и думают, что все и так хорошо будет. Да они правы на 99%, ведь если у вашего сайта нет этого файла, то поисковые системы безграничны в своих поисках контента, но случаются нюансы, над ошибками которых, можно позаботиться заранее.
Если у вас возникли проблемы с этим файлом на сайте, пишите комментарии к этой статье и я быстро помогу вам в этом, абсолютно бесплатно. Очень часто вебмастера делают мелкие ошибки в нем, что приносит сайту плохую индексацию, или вообще исключение из индекса.
Для чего нужен robots.txt
Файл robots.txt создается для настройки правильной индексации сайта поисковым системам. То есть в нем содержатся правила разрешений и запретов на определенные пути вашего сайта или тип контента. Но это не панацея. Все правила в файле robots не являются указаниями точно им следовать, а просто рекомендация для поисковых систем. Google например пишет:
Нельзя использовать файл robots.txt, чтобы скрыть страницу из результатов Google Поиска. На нее могут ссылаться другие страницы, и она все равно будет проиндексирована.
Поисковые роботы сами решают что индексировать, а что нет, и как себя вести на сайте. У каждого поисковика свои задачи и свои функции. Как бы мы не хотели, этим способ их не укротить.
Но есть один трюк, который не касается напрямую тематики этой статьи. Чтобы полностью запретить роботам индексировать и показывать страницу в поисковой выдаче, нужно написать:
<meta name="robots" content="noindex" />
Вернемся к robots. Правилами в этой файле можно закрыть или разрешить доступ к следующим типам файлов:
- Неграфические файлы. В основном это html файлы, на которых содержится какая-либо информация. Вы можете закрыть дубликаты страниц, или страницы, которые не несут никакой полезной информации (страницы пагинации, страницы календаря, страницы с архивами, страницы с профилями и т.д.).
- Графические файлы. Если вы хотите, чтобы картинки сайта не отображались в поиске, вы можете это прописать в файле robots.
- Файлы ресурсов. Также с помощью robots вы можете заблокировать индексацию различных скриптов, файлы стилей CSS и другие маловажные ресурсы. Но не стоит блокировать ресурсы, которые отвечают за визуальную часть сайта для посетителей (например, если вы закроете css и js сайта, которые выводят красивые блоки или таблицы, этого не увидит поисковой робот, и будет ругаться на это).
Чтобы наглядно показать, как работает robots, посмотрите на картинку ниже:


Синтаксис файла robots.txt
Для написания правил поисковым системам в файле роботса используются директивы с различными параметрами, с помощью которых следуют роботы. Начнем с самой первой и наверное самой главной директивы:
Директива User-agent
User-agent — Этой директивой вы задает название роботу, которому следует использовать рекомендации в файле. Этих роботов официально в мире интернета — 302 штуки. Вы конечно можете прописать правила для всех по отдельности, но если у вас нет времени на это, просто пропишите:
User-agent: *
*-в данном примере означает «Все». Т.е. ваш файл robots.txt, должен начинаться с того, «для кого именно» предназначен файл. Чтобы не заморачиваться над всеми названиями роботов, просто пропишите «звездочку» в директиве user-agent.
Приведу вам подробные списки роботов популярных поисковых систем:
Google — Googlebot — основной робот
Яндекс — YandexBot — основной индексирующий робот;
Директивы Disallow и Allow
Disallow — самое основное правило в robots, именно с помощью этой директивы вы запрещаете индексировать определенные места вашего сайта. Пишется директива так:
Disallow:
Очень часто можно наблюдать директиву Disallow: пустую, т.е. якобы говоря роботу, что ничего не запрещено на сайте, индексируй что хочешь. Будьте внимательны! Если вы поставите / в disallow, то вы полностью закроете сайт для индексации.
Поэтому самый стандартный вариант robots.txt, который «разрешает индексацию всего сайта для всех поисковых систем» выглядит так:
User-Agent: * Disallow:
Если вы не знаете что писать в robots.txt, но где-то слышали о нем, просто скопируйте код выше, сохраните в файл под названием robots.txt и загрузите его в корень вашего сайта. Или ничего не создавайте, так как и без него роботы будут индексировать все на вашем сайте. Или прочитайте статью до конца, и вы поймете, что закрывать на сайте, а что нет.
По правилам robots, директива disallow должна быть обязательна.
Этой директивой можно запретить как папку, так и отдельный файл.
Если вы хотите запретить папку вам следует написать:
Disallow: /papka/
Если вы хотите запретить определенный файл:
Disallow: /images/img.jpg
Если вы хотите запретить определенные типы файлов:
Disallow: /*.png$
!Регулярные выражения не поддерживаются многими поисковыми системами. Google поддерживает.
Allow — разрешающая директива в Robots.txt. Она разрешает роботу индексировать определенный путь или файл в запрещающей директории. До недавнего времени использовалась только Яндексом. Google догнал это, и тоже начал ее использовать. Например:
Allow: /content Disallow: /
эти директивы запрещают индексировать весь контент сайта, кроме папки content. Или вот еще популярные директивы в последнее время:
Allow: /themplate/*.js Allow: /themplate/*.css Disallow: /themplate
эти значения разрешают индексировать все файлы CSS и JS на сайте, но запрещают индексировать все в папке с вашим шаблоном. За последний год Google очень много отправил писем вебмастерам такого содержания:
Googlebot не может получить доступ к файлам CSS и JS на сайте
И соответствующий комментарий: Мы обнаружили на Вашем сайте проблему, которая может помешать его сканированию. Робот Googlebot не может обработать код JavaScript и/или файлы CSS из-за ограничений в файле robots.txt. Эти данные нужны, чтобы оценить работу сайта. Поэтому если доступ к ресурсам будет заблокирован, то это может ухудшить позиции Вашего сайта в Поиске.
Если вы добавите две директивы allow, которые написаны в последнем коде в ваш Robots.txt, то вы не увидите подобных сообщений от Google.
Использование спецсимволов в robots.txt
Теперь про знаки в директивах. Основные знаки (спецсимволы) в запрещающих или разрешающих это /,*,$
Про слеши (forward slash) «/»
Слеш очень обманчив в robots.txt. Я несколько десятков раз наблюдал интересную ситуацию, когда по незнанию в robots.txt добавляли:
User-Agent: * Disallow: /
Потому, что они где-то прочитали о структуре сайта и скопировали ее себе на сайте. Но, в данном случае вы запрещаете индексацию всего сайта. Чтобы запрещать индексацию именно каталога, со всеми внутренностями вам обязательно нужно ставить / в конце. Если вы например пропишите Disallow: /seo, то абсолютно все ссылки на вашем сайте, в котором есть слово seo — не будут индексироваться. Хоть это будет папка /seo/, хоть это будет категория /seo-tool/, хоть это будет статья /seo-best-of-the-best-soft.html, все это не будет индексироваться.
Внимательно смотрите на все / в вашем robots.txt
Всегда в конце директорий ставьте /. Если вы поставите / в Disallow, вы запретите индексацию всего сайта, но если вы не поставите / в Allow, вы также запретите индексацию всего сайта. / — в некотором понимании означает «Все что следует после директивы /».
Про звездочки * в robots.txt
Спецсимвол * означает любую (в том числе пустую) последовательность символов. Вы можете ее использовать в любом месте robots по примеру:
User-agent: * Disallow: /papka/*.aspx Disallow: /*old
Запрещает все файлы с расширением aspx в директории papka, также запрещает не только папку /old, но и директиву /papka/old. Замудрено? Вот и я вам не рекомендую баловаться символом * в вашем robots.
По умолчанию в файле правил индексации и запрета robots.txt стоит * на всех директивах!
Про спецсимвол $
Спецсимвол $ в robots заканчивает действие спецсимвола *. Например:
Disallow: /menu$
Это правило запрещает ‘/menu’, но не запрещает ‘/menu.html’, т.е. файл запрещает поисковым системам только директиву /menu, и не может запретить все файлы со словом menu в URL`е.
Директива host
Правило host работает только в Яндекс, поэтому является не обязательным, оно определяет основной домен из ваших зеркал сайта, если таковы есть. Например у вас есть домен dom.com, но и так же прикуплены и настроены следующие домены: dom2.com, dom3,com, dom4.com и с них идет редирект на основной домен dom.com
Чтобы Яндексу быстрее определить, где из них главных сайт (хост), пропишите директорию host в ваш robots.txt:
Host: staurus.net
Если у вашего сайта нет зеркал, то можете не прописывать это правило. Но сначала проверьте ваш сайт по IP адрессу, возможно и по нему открывается ваша главная страница, и вам следует прописать главное зеркало. Или возможно кто-то скопировал всю информацию с вашего сайта и сделал точную копию, запись в robots.txt, если она также была украдена, поможет вам в этом.
Запись host должны быть одна, и если нужно, с прописанным портом. (Host: staurus.net:8080)
Директива Crawl-delay
Эта директива была создана для того, чтобы убрать возможность нагрузки на ваш сервер. Поисковые роботы могут одновременно делать сотни запросов на ваш сайт и если ваш сервер слабый, это может вызвать незначительные сбои. Чтобы такого не произошло, придумали правило для роботов Crawl-delay — это минимальный период между загрузками страницы вашего сайта. Стандартное значение для этой директивы рекомендуют ставить 2 секунды. В Robots это выглядит так:
Crawl-delay: 2
Эта директива работает для Яндекса. В Google вы можете выставить частоту сканирования в панеле вебмастера, в разделе Настройки сайта, в правом верхнем углу с «шестеренкой».
Директива Clean-param
Этот параметр тоже только для Яндекса. Если адреса страниц сайта содержат динамические параметры, которые не влияют на их содержимое (например: идентификаторы сессий, пользователей, рефереров и т. п.), вы можете описать их с помощью директивы Clean-param.
Робот Яндекса, используя эту информацию, не будет многократно перезагружать дублирующуюся информацию. Таким образом, увеличится эффективность обхода вашего сайта, снизится нагрузка на сервер.
Например, на сайте есть страницы:
www.site.com/some_dir/get_book.pl?ref=site_1&book_id=123
www.site.com/some_dir/get_book.pl?ref=site_2&book_id=123
www.site.com/some_dir/get_book.pl?ref=site_3&book_id=123
Параметр ref используется только для того, чтобы отследить с какого ресурса был сделан запрос и не меняет содержимое, по всем трем адресам будет показана одна и та же страница с книгой book_id=123. Тогда, если указать директиву следующим образом:
User-agent: Yandex Disallow: Clean-param: ref /some_dir/get_book.pl
робот Яндекса сведет все адреса страницы к одному:
www.site.com/some_dir/get_book.pl?ref=site_1&book_id=123,
Если на сайте доступна страница без параметров:
www.site.com/some_dir/get_book.pl?book_id=123
то все сведется именно к ней, когда она будет проиндексирована роботом. Другие страницы вашего сайта будут обходиться чаще, так как нет необходимости обновлять страницы:
www.site.com/some_dir/get_book.pl?ref=site_2&book_id=123
www.site.com/some_dir/get_book.pl?ref=site_3&book_id=123
#для адресов вида: www.site1.com/forum/showthread.php?s=681498b9648949605&t=8243 www.site1.com/forum/showthread.php?s=1e71c4427317a117a&t=8243 #robots.txt будет содержать: User-agent: Yandex Disallow: Clean-param: s /forum/showthread.php
Директива Sitemap
Этой директивой вы просто указываете месторасположение вашего sitemap.xml. Робот запоминает это, «говорит вам спасибо», и постоянно анализирует его по заданному пути. Выглядит это так:
Sitemap: http://staurus.net/sitemap.xml
Общие вопросы и рекомендации по robots
А сейчас давайте рассмотрим общие вопросы, которые возникают при составлении роботса. В интернете много таких тем, поэтому разберем самые актуальные и самые частые.
Правильный robots.txt
Очень много но в этом слове «правильный», ведь для одного сайта на одной CMS он будет правильный, а на другой CMS — будет выдавать ошибки. «Правильно настроенный» для каждого сайта индивидуальный. В Robots.txt нужно закрывать от индексации те разделы и те файлы, которые не нужны пользователям и не несут никакой ценности для поисковиков. Самый простой и самый правильный вариант robots.txt
User-Agent: * Disallow: Sitemap: http://staurus.net/sitemap.xml User-agent: Yandex Disallow: Host: site.com
В этом файле стоят такие правила: настройки правил запрета для всех поисковых систем (User-Agent: *), полностью разрешена индексация всего сайта («Disallow:» или можете указать «Allow: /»), указан хост основного зеркала для Яндекса (Host: site.ncom) и месторасположение вашего Sitemap.xml (Sitemap: .
Robots.txt для WordPress
Опять же много вопросов, один сайт может быть интернет-магазинов, другой блог, третий — лендинг, четвертый — сайт-визитка фирмы, и это все может быть на CMS WordPress и правила для роботов будут совершенно разные. Вот мой robots.txt для этого блога:
User-Agent: * Allow: /wp-content/uploads/ Allow: /wp-content/*.js$ Allow: /wp-content/*.css$ Allow: /wp-includes/*.js$ Allow: /wp-includes/*.css$ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /template.html Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content Disallow: /category Disallow: /archive Disallow: */trackback/ Disallow: */feed/ Disallow: /?feed= Disallow: /job Disallow: /?s= Host: staurus.net Sitemap: http://staurus.net/sitemap.xml
Тут очень много настроек, давайте их разберем вместе.
Allow в WordPress. Первые разрешающие правила для контента, который нужен пользователям (это картинки в папке uploads), и роботам (это CSS и JS для отображения страниц). Именно по css и js часто ругается Google, поэтому мы оставили их открытыми. Можно было использовать метод всех файлов просто вставив «/*.css$», но запрещающая строка именно этих папок, где лежат файлы — не разрешала использовать их для индексации, поэтому пришлось прописать путь к запрещающей папке полностью.
Allow всегда указывает на путь запрещенного в Disallow контента. Если у вас что-то не запрещено, не стоит ему прописывать allow, якобы думая, что вы даете толчок поисковикам, типа «Ну на же, вот тебе URL, индексируй быстрее». Так не получится.
Disallow в WordPress. Запрещать в CMS WP нужно очень многое. Множество различных плагинов, множество различных настроек и тем, куча скриптов и различных страниц, которые не несут в себе никакой полезной информации. Но я пошел дальше и совсем запретил индексировать все на своем блоге, кроме самих статей (записи) и страниц (об Авторе, Услуги). Я закрыл даже категории в блоге, открою, когда они будут оптимизированы под запросы и когда там появится текстовое описание для каждой из них, но сейчас это просто дубли превьюшек записей, которые не нужны поисковикам.
Ну Host и Sitemap стандартные директивы. Только нужно было вынести host отдельно для Яндекса, но я не стал заморачиваться по этому поводу. Вот пожалуй и закончим с Robots.txt для WP.
Как создать robots.txt
Это не так сложно как кажется на первый взгляд. Вам достаточно взять обычный блокнот (Notepad) и скопировать туда данные для вашего сайта по настройкам из этой статьи. Но если и это для вас сложно, в интернете есть ресурсы, которые позволяют генерировать роботс для ваших сайтов:
Генератор Robots от pr-cy — Один из самых простых генераторов Robots в Рунете. Просто укажите в инструменте ссылки, которым не стоит попадать в индекс и все.
Создание Robots от htmlweb — хороший генератор robots с возможность добавления host и Sitemap.
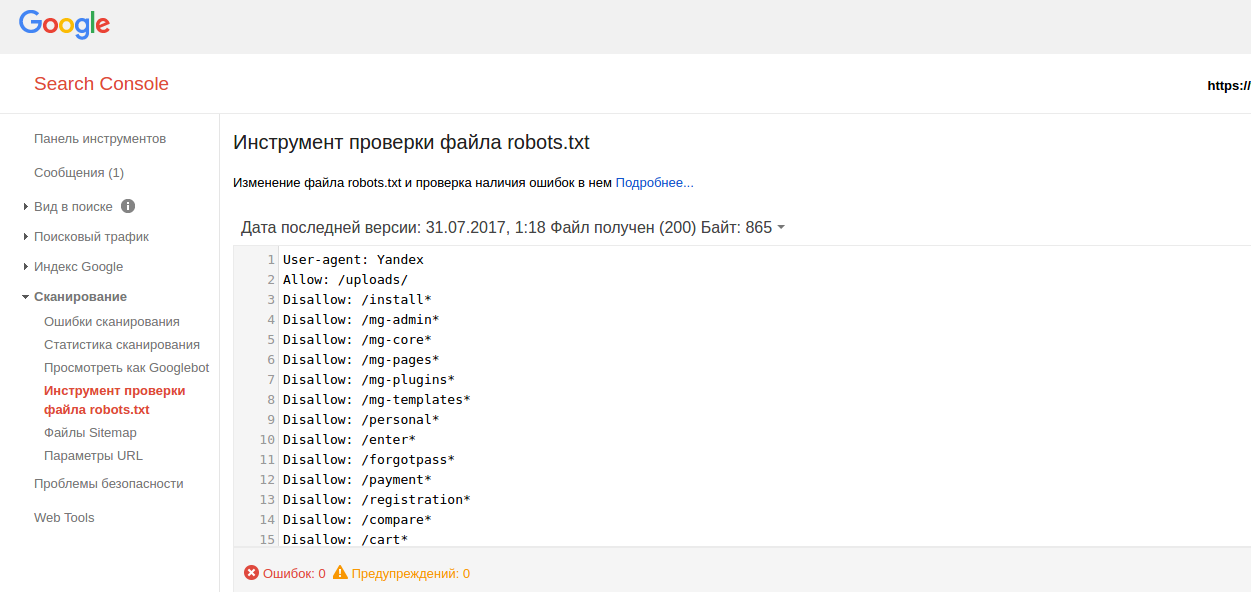
Где проверить свой robots.txt
Это один из самых важный и обязательных пунктов перед отправкой файла роботс на свой сервер — проверка. Если вы, что-то сделали не правильно, вы можете «похоронить» свой сайт в просторах поисковиков. Обычным ляпом, как это случается, запретить индексацию всего сайта.
Чтобы этого не произошло, вам стоит проверить свой файл запретов в одном из удобных проверочных сервисов:
Google Webmaster tool
Яндекс. Вебмастер
Никто не расскажет больше про ваш Robots.txt, как эти товарищи. Ведь именно для них вы и создаете свой «запретный файлик».
Теперь поговорим о некоторых мелких ошибках, которые могут быть в robots.
- «Пустая строка» — недопустимо делать пустую строку в директиве user-agent.
- При конфликте между двумя директивами с префиксами одинаковой длины приоритет отдается директиве Allow.
- Для каждого файла robots.txt обрабатывается только одна директива Host. Если в файле указано несколько директив, робот использует первую.
- Директива Clean-Param является межсекционной, поэтому может быть указана в любом месте файла robots.txt. В случае, если директив указано несколько, все они будут учтены роботом.
- Шесть роботов Яндекса не следуют правилам Robots.txt (YaDirectFetcher, YandexCalendar, YandexDirect, YandexDirectDyn, YandexMobileBot, YandexAccessibilityBot). Чтобы запретить им индексацию на сайте, следует сделать отдельные параметры user-agent для каждого из них.
- Директива User-agent, всегда должна писаться выше запрещающей директивы.
- Одна строка, для одной директории. Нельзя писать множество директорий на одной строке.
- Имя файл должно быть только таким: robots.txt. Никаких Robots.txt, ROBOTS.txt, и так далее. Только маленькие буквы в названии.
- В директиве host следует писать путь к домену без http и без слешей. Неправильно: Host: http://www.site.ru/, Правильно: Host: www.site.ru
- При использовании сайтом защищенного протокола https в директиве host (для робота Яндекса) нужно обязательно указывать именно с протоколом, так Host: https://www.site.ru
Эта статья будет обновляться по мере поступления интересных вопросов и нюансов.
С вами был, ленивый Staurus.
staurus.net
Основные правила настройки robots.txt
Перед тем, как приступить к настройке роботса для вашего сайта, советую ознакомиться с официальными рекомендациями Яндекс и Google. Однако, как обычно и бывает, информация там не  очень легкая для восприятия, именно поэтому я пишу данный гайд.
очень легкая для восприятия, именно поэтому я пишу данный гайд.
Теперь о том, что должно быть в файле robots.txt. По моему мнению, в нем необходимо создавать 3 отдельные наборы директив — для Яндекс, для Google, и для остальных роботов-краулеров. Почему отдельно? Да потому что есть директивы, предназначенные только для определенных ПС, а также можете считать это неким проявлением уважения к основным поисковикам рунета 🙂
Следовательно, роботс должен состоять из таких секций:
Между наборами директив для разных роботов необходимо оставлять пустую строку.
В robots.txt необходимо указать путь к XML карте сайта. Директива является межсекционной, поэтому она может быть размещена в любом месте файла, однако перед ней рекомендуется вставить пустой перевод строки. Запись должна выглядеть так:
Адрес сайта и сам путь к карте необходимо заменить на те, которые являются актуальными для вашего сайта. Также следует помнить, что для сайтов с большим количеством страниц (более 50 000) необходимо создать несколько карт и все их прописать в роботсе.
Настройка robots.txt для Яндекс
Для того, чтобы наглядно показать правильную настройку директив для Яши, я возьму в качестве примера стандартный robots.txt для WordPress.
Обратите внимание на отсутствие директивы Host для Яндекса. Она указывала пауку-роботу Яндекса, какое из зеркал сайта является главным. Директива прекратила существование в начале весны 2018 года, о чем есть соответствующая запись в блоге Яндекса.
Проверить корректность настройки robots.txt для Яндекса можно при помощи данного сервиса.
Настройка robots.txt для Google
Для Google настройка роботса мало чем отличается от уже написанного выше. Однако, есть пара моментов, на которые следует обратить внимание.
Как видно из примера, появились две директивы, разрешающие индексировать JS скрипты и CSS таблицы. Это связано с рекомендацией Google, в которой говорится, что следует разрешать роботу индексировать файлы шаблона (темы) сайта. Естественно, скрипты и таблицы в поиск не попадут, однако это позволит роботам корректнее индексировать сайт и отображать его в результатах выдачи. Данные директивы я внедрил не на один десяток сайтов и по крайней мере, лишние страницы в выдаче не появились.
Ну а корректность настройки директив для Google вы можете проверить инструментом проверки файла robots.txt, который находится в Google Webmaster Tools.
Что еще стоит закрывать в роботсе?
Конечно, статья была бы далеко не полной, если бы я не рассказал, какие файлы и папки следует закрывать от индексирования.
- Страницы поиска. Тут кое-кто может поспорить, так как бывают случаи, когда на сайте используют внутренний поиск именно для создания релевантных страниц. Однако, так поступают далеко не всегда и в большинстве случаев открытые результаты поиска могут наплодить невероятное количество дублей. Поэтому мой вердикт — закрыть.
- Корзина и страница оформления/подтверждения заказа. Данная рекомендация актуальна для интернет-магазинов и других коммерческих сайтов, где есть форма заказа. Данные страницы ни в коем случае не должны попадать в индекс ПС.
- Фильтры и сравнение товаров. Рекомендация относится к интернет-магазинам и сайтам-каталогам.
- Страницы регистрации и авторизации. Информация, которая вводится при регистрации или входе на сайт, является конфиденциальной. Поэтому следует избегать индексации подобных страниц, Google это оценит.
- Системные каталоги и файлы. Каждый сайт состоит из множества данных — скриптов, таблиц CSS, административной части. Такие файлы следует также ограничить для просмотра роботам.
Замечу, что для выполнения некоторых из вышеописанных пунктов можно использовать и другие инструменты, например, rel=canonical, про который я позже напишу в отдельной статье. Кроме этого, не подходите к рекомендациям буквально — всегда есть исключения. Например, фильтры в некоторых магазинах имеют свои чпу, уникальные мета, контент. Конечно, не надо такие страницы закрывать — это дополнительные релевантные страницы под ключи.
Мой вариант robots.txt для WordPress и Joomla
Дописываю эти строки спустя какое-то время после написания статьи. Дело в том, что несмотря на пользу различных директив и объяснении мною их функций, я забыл добавить информацию о том, как должен выглядеть роботс в конечном итоге. Поэтому добавляю мои наборы директив для двух моих любимых и часто используемых CMS — WordPress и Joomla. Естественно, не забывайте, что некоторые параметры вам понадобится дописать самим, поэтому обязательно ознакомьтесь с рекомендациями Google и Яндекс (ссылки на оф. источники во втором абзаце данной статьи).
robots.txt для WordPress
Обратите внимание, что директиву Sitemap в вашем роботсе нужно заменить на необходимые вам.
robots.txt для Joomla
Замечу, что в наборе поисковых правил для Joomla я закрыл пагинацию страниц в разделах, а также страницу поиска по сайту. Если вам необходимы данные страницы в поиске — можете убрать из robots.txt эти две строчки:
Немного о нестандартном использовании robots.txt
С учетом написанного выше, тему правильной настройки robots.txt можно считать раскрытой, однако есть еще кое-что, о чем я бы хотел рассказать. Роботс можно с пользой применять помимо назначения и без вреда для сайта. Дело в том, что в файле можно использовать такой знак, как «#» — он обозначает комментарии, не учитываемые роботами. Данный знак действителен в пределах одной строки, там, где он используется. Его можно использовать для пометок, чтобы не забыть, что и зачем было закрыто от поисковых систем.
Но есть и другое применение. Например, после знака комментария, вы можете разместить полезную информацию: контакты сайта, вакансию для оптимизатора, ссылку на важную информацию, и даже рекламу. Не буду заниматься плагиатом, так как идея не моя, поэтому предлагаю ознакомиться с различными вариантами на блоге Devaka. Уверен, вы будете удивлены, узнав, насколько разнообразным может быть использование роботса не по назначению.
На этом все, правильная настройка robots.txt описана в полной мере, надеюсь, вы узнали что-то новое. Если же после прочтения статьи у вас остались вопросы — задавайте их в комментариях, и я постараюсь на них ответить.
sky-fi.info
Что такое robots txt
В одной из наших прошлых статей мы рассказывали и том, как работают поисковые роботы. Файл robots txt даёт инструкции поисковым роботам, о том, как правильно индексировать ваш сайт. С помощью директив вы можете, например, указать роботу какие страницы или директории следует индексировать, а какие нет, сформировать группу зеркал для вашего сайта(если они у вас есть), указать путь к файлу sitemap и так далее. В основном его используют именно для запрета индексации определённых страниц сайта.

Как создать правильный robots txt
В любом текстовом редакторе создайте файл с именем robots txt. Затем, используя директивы описанные ниже, укажите роботу на страницы сайта, которые надо добавить или же наоборот убрать из поисковой выдачи. После того, как вы создали файл, проверьте его на наличие ошибок с помощью Яндекс вебмастера или Google Search Console.
Готовый файл поместите в корневой каталог вашего сайта(там, где находится файл index.html).
Директива User-agent
Это своеобразное приветствие поисковых роботов.
Строка «User-agent:*» Скажет, что все поисковые роботы могут использовать инструкции, содержащиеся в этом файле. А, например, строка «User-agent: Yandex» даст инструкции только для поискового робота яндекса. Примеры использования указаны ниже. Также у поисковых систем есть вспомогательные роботы для разных категорий. Например, YandexNews и Googlebot-News — это роботы для работы с новостями.
Директивы Allow и Disallow
С помощью директивы Disallow вы указываете какие страницы или каталоги сайта запрещено индексировать. А с помощью директивы Allow, соответственно, можно.
Примеры:
User-agent:*
Disallow: /
Allow:/catalog/
Такая запись сообщит всем поисковым роботам, что из всего сайта им можно индексировать только директорию catalog.
Кстати, символ # предназначен для описания комментариев. Все, что находится после этого символа и до конца строки не учитывается.
А вот пример robots txt с указанием индивидуальных инструкций для разных поисковиков:
#разрешает роботу индексировать весь сайт, кроме раздела с велосипедами
User-agent:*
Disallow: /велосипеды/
#запрещает роботу индексировать сайт, кроме раздела с лодками
User-agent: Googlebot
Allow: /лодки/
Disallow:/
#запретит всем остальным поисковым системам индексировать сайт
User-agent: *
Disallow: /
Обратите внимание, что между директивами User-agent, Allow и Disallow не может быть пустых строк!
Спецсимволы * и $
В директивах allow и Disallow можно использовать спецсимволы * и $, чтобы задавать регулярные выражения. *-выбирает указанную последовательность
Например:
#Запрещает роботам индексировать все страницы, url которых содержит private
User-agent:*
Disallow: /*private
По умолчанию в конце каждого правила необходимо прописать спецсимвол *. А чтобы отменить * в конце правила используется символ $.
Например:
# запрещает ‘/lock’
# но не запрещает ‘/lock.html’
User-agent:*
Disallow: /lock$
# запрещает и ‘/lock’
# и ‘/lock.html’
User-agent:*
Disallow: /lock
Спецсимвол $ не запрещает указанный * на конце, то есть:
User-agent:*
Disallow: /lock$ # запрещает только ‘/lock’
Disallow: /lock*$ # так же, как ‘Disallow: /lock’
# запрещает и /lock.html и /lock
Директива sitemap
Если вы используете карту сайта sitemap, то используйте директиву sitemap и в ней укажите путь к одному(или нескольким файлам).
User-agent:*
sitemap:https://site.com/sitemap.xml
Директива Host
Если у вашего сайта есть зеркала, то с помощью этой директивы специальный робот сформирует группу зеркал вашего сайта, а в поиск внесет только главное зеркало. Эта директива не гарантирует выбор указанного сайта в ней в качестве главного зеркала, но даёт ему высокий приоритет при принятии решения.
Пример:
#указываем главное зеркало сайта
User-Agent: Yandex
Disallow:/mg-admin
Host: https://www.zerkalo.ru
Примечание. Эта директива используется исключительно для Яндекса! + Для каждого файла robots.txt обрабатывается только одна директива Host. Если в файле указано несколько директив, робот использует первую.
Директива Host должна содержать:
- Протокол HTTPS, если зеркало доступно только по защищенному каналу. Если вы используете протокол HTTP, то его указывать необязательно.
- Одно корректное доменное имя, соответствующего RFC 952 и не являющегося IP-адресом.
- Номер порта, если необходимо (Host: myhost.ru:8080).
Можно ли использовать кириллицу в robots txt?
Нет, использовать кириллицу нельзя. Для указания имен доменов на кириллице используйте, например, этот сервис.
Настройка robots txt MogutaCMS
В MogutaCMS заполнять robots.txt не требуется, т.к. он заполняется автоматически при установке движка.
Теперь вы знаете, как задать правильный robots txt, а также знаете как использовать различные директивы для управления индексацией своего сайта, а если у вас остались какие-либо вопросы, то мы готови ответить на них в специальном обсуждении в вк или же в комментариях ниже. До новых встреч!
moguta.ru
Начало работы
Файл robots.txt находится в корневом каталоге вашего сайта. Например, на сайте www.example.com адрес файла robots.txt будет выглядеть как www.example.com/robots.txt. Он представляет собой обычный текстовый файл, который соответствует стандарту исключений для роботов, и включает одно или несколько правил, каждое из которых запрещает или разрешает тому или иному поисковому роботу доступ к определенному пути на сайте.
Ниже приведен пример простого файла robots.txt, содержащего два правила, и его интерпретация.
# Rule 1 User-agent: Googlebot Disallow: /nogooglebot/ # Rule 2 User-agent: * Allow: / Sitemap: http://www.example.com/sitemap.xml
Интерпретация
- Агент пользователя с названием Googlebot не должен сканировать каталог
http://example.com/nogooglebot/и его подкаталоги. - У всех остальных агентов пользователя есть доступ ко всему сайту (можно опустить, результат будет тем же, так как полный доступ предоставляется по умолчанию).
- Файл Sitemap этого сайта находится по адресу http://www.example.com/sitemap.xml.
Далее представлен более подробный пример.
Основные рекомендации в отношении файлов robots.txt
Ниже представлено несколько советов по работе с файлами robots.txt. Мы рекомендуем вам изучить полный синтаксис файлов robots.txt, так как используемые при создании файлов robots.txt синтаксические правила являются неочевидными и вы должны разбираться в них.
Формат и расположение
Создать файл robots.txt можно почти в любом текстовом редакторе (он должен поддерживать кодировку ASCII или UTF-8). Не используйте текстовые процессоры: зачастую они сохраняют файлы в проприетарном формате и добавляют в них недопустимые символы, например фигурные кавычки, которые не распознаются поисковыми роботами.
Правила в отношении формата и расположения файла
- Файл должен носить название robots.txt.
- На сайте должен быть только один такой файл.
- Файл robots.txt нужно разместить в корневом каталоге сайта. Например, чтобы контролировать сканирование всех страниц сайта
http://www.example.com/, файл robots.txt следует разместить по адресуhttp://www.example.com/robots.txt. Он не должен находиться в подкаталоге (например, по адресуhttp://example.com/pages/robots.txt). В случае затруднений с доступом к корневому каталогу обратитесь к хостинг-провайдеру. Если у вас нет доступа к корневому каталогу сайта, используйте альтернативный метод блокировки, например метатеги. - Файл robots.txt можно добавлять по адресам с субдоменами (например,
http://website.example.com/robots.txt) или нестандартными портами (например,http://example.com:8181/robots.txt). - Комментариями являются любые строки, начинающиеся с символа решетки (#).
Синтаксис
- Файл robots.txt должен являться текстовым файлом в кодировке ASCII или UTF-8. Использовать другие символы не разрешается.
- Файл robots.txt может состоять из одного или нескольких правил.
- Правило должно содержать несколько директив (инструкций), каждую из которых следует указывать на отдельной строке.
- Правило содержит следующую информацию:
- К какому агенту пользователя относится правило.
- К каким каталогам или файлам у этого агента есть доступ.
- К каким каталогам или файлам у этого агента нет доступа.
- Правила обрабатываются сверху вниз. Агент пользователя может следовать только одному подходящему для него правилу, которое будет обработано первым.
- По умолчанию предполагается, что если доступ к странице или каталогу не заблокирован правилом
Disallow:, агент пользователя может их обрабатывать. - Правила чувствительны к регистру. Так, правило
Disallow: /file.aspприменимо к URLhttp://www.example.com/file.asp, но не кhttp://www.example.com/File.asp.
Директивы, которые используются в файлах robots.txt
User-agent:Обязательно к использованию, в одном правиле может быть одно или несколько таких правил. Определяет робота поисковой системы, к которому относится правило. Эта строка является первой в любом правиле. Большинство из них перечислены в базе данных роботов Интернета или в списке поисковых роботов Google. Поддерживается подстановочный знак * для обозначения префикса или суффикса пути или всего пути. Используйте такой знак (*), как указано в примере ниже, чтобы заблокировать все поисковые роботы (кроме роботов AdsBot, которых нужно задавать отдельно). Рекомендуем ознакомиться со списком роботов Google. Примеры:# Example 1: Block only Googlebot User-agent: Googlebot Disallow: / # Example 2: Block Googlebot and Adsbot User-agent: Googlebot User-agent: AdsBot-Google Disallow: / # Example 3: Block all but AdsBot crawlers User-agent: * Disallow: /
Disallow:В каждом правиле должна быть по крайней мере одна директива Disallow: или Allow:. Указывает на каталог или страницу в корневом домене, которые нельзя сканировать агенту пользователя, определенному выше. Если это страница, должен быть указан полный путь к ней, как в адресной строке браузера. Если это каталог, путь к нему должен заканчиваться косой чертой (/). Поддерживается подстановочный знак * для обозначения префикса или суффикса пути или всего пути.Allow:В каждом правиле должна быть по крайней мере одна директива Disallow: или Allow:. Указывает на каталог или страницу в корневом домене, которые нельзя сканировать агенту пользователя, определенному выше. Используется для того, чтобы отменить правило Disallow и разрешить сканирование подкаталога или страницы в закрытом для сканирования каталоге. Если это страница, должен быть указан полный путь к ней, как в адресной строке браузера. Если это каталог, путь к нему должен заканчиваться косой чертой (/). Поддерживается подстановочный знак * для обозначения префикса или суффикса пути или всего пути.Sitemap:Необязательно, таких директив может быть несколько или совсем не быть. Указывает на расположение файла Sitemap, используемого на этом сайте. URL должен быть полным. Google не обрабатывает и не проверяет варианты URL с префиксами http и https или с элементом www и без него. Файлы Sitemap сообщают Google, какой контент нужно сканировать и как отличить его от контента, который можно или нельзя сканировать. Ознакомьтесь с дополнительными сведениями о файлах Sitemap. Пример:Sitemap: https://example.com/sitemap.xml Sitemap: http://www.example.com/sitemap.xml
Неизвестные ключевые слова игнорируются.
Ещё один пример
Файл robots.txt состоит из одного или нескольких наборов правил. Каждый набор начинается с строки User-agent, которая определяет робота, подчиняющегося правилам в наборе. Вот пример файла с двумя правилами; они объяснены встроенными комментариями:
# Блокировать доступ робота Googlebot к каталогам example.com/directory1/... и example.com/directory2/... # но разрешить доступ к каталогу directory2/subdirectory1/... # Доступ ко всем остальным каталогам разрешен по умолчанию. User-agent: googlebot Disallow: /directory1/ Disallow: /directory2/ Allow: /directory2/subdirectory1/ # Блокировать доступ ко всему сайту другой поисковой системе. User-agent: anothercrawler Disallow: /
Полный синтаксис файла robots.txt
Полный синтаксис описан в этой статье. Рекомендуем вам ознакомиться с ней, так как в синтаксисе файла robots.txt есть некоторые важные нюансы.
Полезные правила
Вот несколько распространенных правил для файла robots.txt:
| Правило | Пример |
|---|---|
| Запрет сканирования всего сайта. Следует учесть, что в некоторых случаях URL сайта могут присутствовать в индексе, даже если они не были просканированы. Обратите внимание, что это правило не относится к роботам AdsBot, которых нужно указывать отдельно. |
User-agent: * Disallow: / |
| Чтобы запретить сканирование каталога и все его содержание, поставьте после названия каталога косую черту. Не используйте файл robots.txt для защиты конфиденциальной информации! Для этих целей следует применять аутентификацию. URL, сканирование которых запрещено файлом robots.txt, могут быть проиндексированы, а содержание файла robots.txt может просмотреть любой пользователь, и таким образом узнать местоположение файлов с конфиденциальной информацией. |
User-agent: * Disallow: /calendar/ Disallow: /junk/ |
| Разрешение сканирования только для одного поискового робота |
User-agent: Googlebot-news Allow: / User-agent: * Disallow: / |
| Разрешение сканирования для всех поисковых роботов, за исключением одного |
User-agent: Unnecessarybot Disallow: / User-agent: * Allow: / |
|
Чтобы запретить сканирование отдельной страницы, укажите эту страницу после косой черты. |
Disallow: /private_file.html |
|
Чтобы скрыть определенное изображение от робота Google Картинок |
User-agent: Googlebot-Image Disallow: /images/dogs.jpg |
|
Чтобы скрыть все изображения с вашего сайта от робота Google Картинок |
User-agent: Googlebot-Image Disallow: / |
|
Чтобы запретить сканирование всех файлов определенного типа (в данном случае |
User-agent: Googlebot Disallow: /*.gif$ |
|
Чтобы заблокировать определенные страницы сайта, но продолжать на них показ объявлений AdSense, используйте правило Disallow для всех роботов, за исключением Mediapartners-Google. В результате этот робот сможет получить доступ к удаленным из результатов поиска страницам, чтобы подобрать объявления для показа тому или иному пользователю. |
User-agent: * Disallow: / User-agent: Mediapartners-Google Allow: / |
Чтобы указать URL, заканчивающиеся на определенные символы, применяйте символ $. Например, для URL, заканчивающихся на .xls, используйте следующий код: |
User-agent: Googlebot Disallow: /*.xls$ |
support.google.com
Зачем robots.txt в SEO?
Первое, на что обращает внимание оптимизатор при анализе/начале продвижения сайта — это роботс. Именно в нем располагаются все главные инструкции, которые касаются действий индексирующего робота. Именно в robots.txt мы исключаем из поиска страницы, прописываем пути к карте сайта, определяем главной зеркало сайта, а так же вносим другие важные инструкции.
Ошибки в директивах могут привести к полному исключению сайта из индекса. Отнестись к настройкам данного файла нужно осознано и очень серьезно, от этого будет зависеть будущий органический трафик.
Создаем robots самостоятельно
Сам процесс создания файла до безобразия прост. Необходимо просто создать текстовой документ, назвав его «robots». После этого, подключившись через FTP соединение, загрузить в корневую папку Вашего сайта. Обязательно проверьте, что бы роботс был доступен по адресу ваш домен/robots.txt. Не допускается наличие вложений, к примеру ваш домен/page/robots.txt.
Если Вы пользуетесь web ftp — файловым менеджером, который доступен в панели управления у любого хост-провайдера, то файл можно создать прямо там.
В итоге, у нас получается пустой роботс. Все инструкции мы будем вписывать вручную. Как это сделать, мы опишем ниже.
Используем online генераторы
Если создание своими руками это не для Вас, то существует множество online генераторов, которые помогут в этом. Но нужно помнить, что никакой генератор не сможет без Вас исключить из поиска весь «мусор» и не добавит главное зеркало, если Вы не знаете какое оно. Данный вариант подойдет лишь тем, кто не хочет писать рутинные повторяющиеся для большинства сайтов инструкции.
Сгенерированный онлайн роботс нужно будет в любом случае править «руками», поэтому без знаний синтаксиса и основ Вам не обойтись и в этом случае.
Используем готовые шаблоны
В Интернете есть множество шаблонов для распространенных CMS, таких как WordPress, Joomla!, MODx и т.д. От онлайн генераторов они отличаются только тем, что сам текстовой файл Вам нужно будет сделать самостоятельно. Шаблон позволяет не писать большинство стандартных директив, однако он не гарантирует правильную и полную настройку для Вашего ресурса. При использовании шаблонов так же нужны знания.
Синтаксис robots.txt
Использование правильного синтаксиса при настройке — это основа всего. Пропущенная запятая, слэш, звездочка или проблем могут «сбить» всю настройку. Безусловно, есть системы проверки файла, однако без знания синтаксиса они все равно не помогу. Мы по порядку рассмотрим все возможные инструкции, которые применяются при настройке robots.txt. Сначала самые популярные.
Обращение к индексирующему роботу
Любой файл robots начинается с директивы User-agent:, которая указывает для какой поисковой системы или для какого робота приведены инструкции ниже. Пример использования:
User-agent: Yandex User-agent: YandexBot User-agent: Googlebot
Строка 1 — Инструкции для всех роботов Яндекса
Строка 2 — Инструкции для основного индексирующего робота Яндекса
Строка 3 — Инструкции для основного индексирующего робота Google
Яндекс и Гугл имеют не один и даже не два робота. Действиями каждого можно управлять в нашем robots.txt. Давайте рассмотрим, какие бывают роботы и зачем они нужны.
Роботы Yandex
| Название | Описание | Предназначение |
| YandexBot | Основной индексирующий робот | Отвечает за основную органическую выдачу Яндекса. |
| YandexDirect | Работ контекстной рекламы | Оценивает сайты с точки зрения расположения на них контекстных объявлений. |
| YandexDirectDyn | Так же робот контекста | Отличается от предыдущего тем, что работает с динамическими баннерами. |
| YandexMedia | Индексация мультимедийных данных. | Отвечает, загружает и оценивает все, что связано с мультимедийными данными. |
| YandexImages | Индексация изображений | Отвечает за раздел Яндекса «Картинки» |
| YaDirectFetcher | Так же робот Яндекс Директ | Его особенность в том, что он интерпретирует файл robots особым образом. Подробнее о нем можно прочесть у Яндекса. |
| YandexBlogs | Индексация блогов | Данный робот отвечает за посты, комментарии, ответы и т.д. |
| YandexNews | Новостной робот | Отвечает за раздел «Новости». Индексирует все, что связано с периодикой. |
| YandexPagechecker | Робот микроразметки | Данный робот отвечает за индексацию и распознание микроразметки сайта. |
| YandexMetrika | Робот Яндекс Метрики | Тут все и так ясно. |
| YandexMarket | Робот Яндекс Маркета | Отвечает за индексацию товаров, описаний, цен и всего того, что относится к Маркету. |
| YandexCalendar | Робот Календаря | Отвечает за индексацию всего, что связано с Яндекс Календарем. |
Роботы Google
| Название | Описание | Предназначение |
| Googlebot | (Googlebot) Основной индексирующий роботом Google. | Индексирует основной текстовой контент страницы. Отвечает за основную органическую выдачу. Запрет приведет к полному отсутствия сайта в поиске. |
| Googlebot-News | (Googlebot News) Новостной робот. | Отвечает за индексирование сайта в новостях. Запрет приведет к отсутствию сайта в разделе «Новости» |
| Googlebot-Image | (Googlebot Images) Индексация изображений. | Отвечает за графический контент сайта. Запрет приведет к отсутствию сайта в выдаче в разделе «Изображения» |
| Googlebot-Video | (Googlebot Video) Индексация видео файлов. | Отвечает за видео контент. Запрет приведет к отсутствию сайта в выдаче в разделе «Видео» |
| Googlebot | (Google Smartphone) Робот для смартфонов. | Основной индексирующий робот для мобильных устройств. |
| Mediapartners-Google | (Google Mobile AdSense) Робот мобильной контекстной рекламы | Индексирует и оценивает сайт с целью размещения релевантных мобильных объявлений. |
| Mediapartners-Google | (Google AdSense) Робот контекстной рекламы | Индексирует и оценивает сайт с целью размещения релевантных объявлений. |
| AdsBot-Google | (Google AdsBot) Проверка качества страницы. | Отвечает за качество целевой страницы — контент, скорость загрузки, навигация и т.д. |
| AdsBot-Google-Mobile-Apps | Робот Google для приложений | Сканирование для мобильных приложений. Оценивает качество так же, как и предыдущий робот AdsBot |
Обычно robots.txt настраивается для всех роботов Яндекса и Гугла сразу. Очень редко приходится делать отдельные настройки для каждого конкретного краулера. Однако это возможно.
Другие поисковые системы, такие как Bing, Mail, Rambler, так же индексируют сайт и обращаются к robots.txt, однако мы не будем заострять на них внимание. Про менее популярные поисковики мы напишем отдельную статью.
Запрет индексации Disallow
Без сомнения самая популярная директива. Именно при помощи disallow страницы исключаются из индекса. Disallow — буквально означает запрет на индексацию страницы, раздела, файла или группы страниц (при помощи маски). Рассмотрим пример:
Disallow: /wp-admin Disallow: /wp-content/plugins Disallow: /img/images.jpg Disallow: /dogovor.pdf Disallow: */trackback Disallow: /*my
Строка 1 — запрет на индексацию всего раздела wp-admin
Строка 2 — запрет на индексацию подраздела plugins
Строка 3 — запрет на индексацию изображения в папке img
Строка 4 — запрет индексации документа
Строка 5 — запрет на индексацию trackback в любой папке на 1 уровень
Строка 6 — запрет на индексацию не только /my, но и /folder/my или /foldermy
Данная директива поддерживает маски, о которых мы подробнее напишем ниже.
После Disallow в обязательном порядке ставится пробел, а вот в конце строки пробела быть не должно. Так же, допускается написание комментария в одной строке с директивой через пробел после символа «#», однако это не рекомендуется.
Указание нескольких каталогов в одной инструкции не допускается!
Разрешение индексации Allow
Обратная Disallow директива Allow разрешает индексацию конкретного раздела. Заходить на Ваш сайт или нет решает поисковая система, но данная директива ей это позволяет. Обычно Allow не применяется, так как поисковая система старается индексировать весь материал сайта, который может быть полезен человеку.
Пример использования Allow
Allow: /img/ Allow: /dogovor.pdf Allow: /trackback.html Allow: /*my
Строка 1 — разрешает индексацию всего каталога /img/
Строка 2 — разрешает индексацию документа
Строка 3 — разрешает индексацию страницы
Строка 4 — разрешает индексацию по маске *my
Данная директива поддерживает и подчиняется всем тем же правилам, которые справедливы для Disallow.
Директива host robots.txt
Данная директива позволяет обозначить главное зеркало сайта. Обычно, зеркала отличаются наличием или отсутствием www. Данная директива применяется в каждом robots и учитывается большинством поисковых систем.
Пример использования:
Host: dh-agency.ru
Если вы не пропишите главное зеркало сайта через host, Яндекс сообщит Вам об этом в Вебмастере.

Не знаете главное зеркало сайта? Определить довольно просто. Вбейте в поиск Яндекса адрес своего сайта и посмотрите выдачу. Если перед доменом присутствует www, то значит главное зеркало у вас с www.
Если же сайт еще не участвует в поиске, то в Яндекс Вебмастере в разделе «Переезд сайта» Вы можете задать главное зеркало самостоятельно.
Sitemap.xml в robots.txt
Данную директиву желательно иметь в каждом robots.txt, так как ее используют yandex, google, а так же все основные поисковые системы. Директива представляет из себя ссылку на файл sitemap.xml в котором содержатся все страницы, которые предназначены для индексирования. Так же в sitemap указываются приоритеты и даты изменения.
Пример использования:
Sitemap: http://dh-agency.ru/sitemap.xml
О том, как правильно создавать sitemap.xml мы напишем чуть позже.
Использование директивы Clean-param
Очень полезная, но мало кем применяющаяся директива. Clean-param позволяет описать динамические части URL, которые не меняют содержимое страницы. Такими динамическими частями могут быть:
- Идентификаторы сессий;
- Идентификаторы пользователей;
- Различные индивидуальные префиксы не меняющие содержимое;
- Другие подобные элементы.
Clean-param позволяет поисковым системам не загружать один и тот же материал многократно, что делает обход сайта роботом намного эффективнее.
Объясним на примере. Предположим, что для определения с какого сайта перешел пользователь мы взяли параметр site. Данный параметр будет меняться в зависимости от ресурса, но контент страницы будет одним и тем же.
http://dh-agency.ru/folder/page.php?site=x&r_id=985 http://dh-agency.ru/folder/page.php?site=y&r_id=985 http://dh-agency.ru/folder/page.php?site=z&r_id=985
Все три ссылки разные, но они отдают одинаковое содержимое страницы, поэтому индексирующий робот загрузит 3 копии контента. Что бы этого избежать пропишем следующие директивы:
User-agent: Yandex Disallow: Clean-param: site /folder/page.php
В данном случае робот Яндекса либо сведет все страницы к одному варианту, либо проиндексирует ссылку без параметра. Если такая конечно есть.
Использование директивы Crawl-delay
Довольно редко используемая директива, которая позволяет задать роботу минимальный промежуток между загружаемыми страницами. Crawl-delay применяется, когда сервер нагружен и не успевает отвечать на запросы. Промежуток задается в секундах. К примеру:
User-agent: Yandex Crawl-delay: 3
В данном случае таймаут будет 3 секунды. Кстати, стоит отметить, что Яндекс поддерживает и не целые значения в данной директиве. К примеру, 0.4 секунды.
Комментарии в robots.txt
Хороший robots.txt всегда пишется с комментариями. Это упростит работу Вам и поможет будущим специалистам.
Что бы написать комментарий, который будет игнорировать робот поисковой системы, необходимо поставить символ «#». К примеру:
#мой роботс Disallow: /wp-admin Disallow: /wp-content/plugins
Так же возможно, но не желательно, использовать комментарий в одной строке с инструкцией.
Disallow: /wp-admin #исключаем wp admin Disallow: /wp-content/plugins
На данный момент никаких технических запретов по написанию комментария в одной строке с инструкцией нету, однако это считается плохим тоном.
Маски в robots.txt
Применение масок в robots.txt не только упрощает работу, но зачастую просто необходимо. Напомним, маска — это условная запись, которая содержит в себе имена нескольких файлов или папок. Маски применяются для групповых операций с файлами/папками. Предположим, что у нас есть список файлов в папке /documents/

Среди этих файлов есть презентации в формате pdf. Мы не хотим, что бы их сканировал робот, поэтому исключаем из поиска.
Мы можем перечислять все файлы формата .pdf «в ручную»
Disallow: /documents/admin.pdf Disallow: /documents/r7.pdf Disallow: /documents/leto.pdf Disallow: /documents/sity.pdf Disallow: /documents/afrika.pdf Disallow: /documents/t-12.pdf
А можем сделать простую маску *.pdf и скрыть все файлы в одной инструкции.
Disallow: /documents/*.pdf
Удобно, не правда ли?
Маски создаются при помощи спецсимвола «*». Он обозначает любую последовательность символов, в том числе и пробел. Примеры использования:
Disallow: *.pdf Disallow: admin*.pdf Disallow: a*m.pdf Disallow: /img/*.* Disallow: img.* Disallow: &amp;=*
Стоит отметить, что по умолчанию спецсимвол «*» добавляется в конце каждой инструкции, которую Вы прописываете. То есть,
Disallow: /wp-admin # равносильно инструкции ниже Disallow: /wp-admin*
То есть, мы исключаем все, что находится в папке /wp-admin, а так же /wp-admin.html, /wp-admin.pdf и т.д. Для того, что бы этого не происходило необходимо в конце инструкции поставить другой спецсимвол — «$».
Disallow: /wp-admin$ #
В таком случае, мы уже не запрещаем файлы /wp-admin.html, /wp-admin.pdf и т.д
Как правильно настроить robots.txt?
С синтаксисом robots.txt мы разобрались выше, поэтому сейчас напишем как правильно настроить данный файл. Если для популярных CMS, таких как WordPress и Joomla!, уже есть готовые robots, то для самописного движка или редкой СУ Вам придется все настраивать вручную.
(Даже несмотря на наличие готовых robots.txt редактировать и удалять «уникальный мусор» Вам придется и в ВордПресс. Поэтому этот раздел будет полезен и для владельцев сайтов на ТОПовых CMS)
Что нужно исключать из индекса?
А.) В первую очередь из индекса исключаются дубликаты страниц в любом виде. Страница на сайте должна быть доступна только по одному адресу. То есть, при обращении к ресурсу робот должен получать по каждому URL уникальный контент.
Зачастую дубликаты появляются у систем управления сайтом при создании страниц. К примеру, одна и та же страница может быть доступна по техническому адресу /?p=391&preview=true и одновременно с этим иметь ЧПУ. Так же дубли могут возникать при работе с динамическими ссылками.
Всех их необходимо при помощи масок исключать из индекса.
Disallow: /*?* Disallow: /*% Disallow: /index.php Disallow: /*?page= Disallow: /*&amp;page=
Б.) Все страницы, которые имеют не уникальный контент, желательно убрать из индекса еще до того, как это сделает поисковая система.
В.) Из индекса должны быть исключены все страницы, которые используются при работе сценариев. К примеру, страница «Спасибо, сообщение отправлено!».
Г.) Желательно исключить все страницы, которые имеют индикаторы сессий
Disallow: *PHPSESSID= Disallow: *session_id=
Д.) В обязательном порядке из индекса должны быть исключены все файлы вашей cms. Это файлы панели администрации, различных баз, тем, шаблонов и т.д.
Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback
Е.) Пустые страницы и разделы, «не нужный» пользователям контент, результаты поиска и работы калькулятора так же должны быть недоступны роботу.
«Держа в чистоте» Ваш индекс Вы упрощаете жизнь и себе и индексирующему роботу.
Что нужно разрешать индексировать?
Да по сути все, что не запрещено. Есть только один нюанс. Поисковые системы по умолчанию индексируют любой полезный контент Вашего сайта, поэтому использовать директиву Allow в 90% случаев не нужно.
Корректный файл sitemap.xml и качественная перелинковка дадут гарантию, что все «нужные» страницы Вашего сайта будут проиндексированы.
Обязательны ли директивы host и sitemap?
Да, данные директивы обязательны. Прописать их не составит труда, но они гарантируют, что робот точно найдет sitemap.xml, и будет «знать» главное зеркало сайта.
Для каких поисковиков настраивать?
Инструкции файла robots.txt понимают все популярные поисковые системы. Если различий в инструкциях нету, то Вы можете прописать User-agent: * (Все директивы для всех поисковиков).
Однако, если Вы укажите инструкции для конкретного робота, к примеру Yandex, то все другие директивы Яндексом будут проигнорированы.
Нужны ли мне директивы Crawl-delay и Clean-param?
Если Вы используете динамические ссылки или же передаете параметры в URL, то Вам скорее всего понадобиться Clean-param, дабы не вводить робота в заблуждение. Использование данной директивы мы описали выше. Данная директива поможет Вам избежать ненужных дубликатов в поиске, что очень важно.
Использование Crawl-delay зависит исключительно от Вашего хостинга. Если Вы чувствуете, что сервер уже не справляется запросами, то желательно увеличить время межу ними.
Проверяем свой robots.txt
После настройки файла его необходимо проверить. Сделать это возможно через Ваш Вебмастер в разделе «Инструменты» -> «Анализ robots.txt»

Но нужно понимать, что данный онлайн инструмент сможет лишь найти синтаксическую ошибку. Он никак не убережет Вас от лишней исключенной страницы, а так же от мусора в выдаче.
dh-agency.ru